AI + Bob:大模型翻译断网可用
初识 Bob:相见恨晚
在 2025 年的第一个月,我接触到了 Bob 这个项目,顿时有种相见恨晚的感觉。它解决了我一个长期存在的痛点:Apple 图书自带的翻译功能无法使用。具体来说,Apple 目前没有办法实现 划词 + 自带字典 的功能(其实到现在我也没解决这个问题,不过这不是今天的重点)。
Bob 的安装与试用体验
正常安装 Bob 之后,翻译功能便可立即启动。目前 Pro 版本提供 14 天试用期。Bob 自带的翻译本质上也是 AI,而语音合成功能则依赖 Mac 的本地引擎,整体效果相当不错。
进一步探索:Google Gemini 与本地 AI 方案
如果想要更进一步,可以尝试 Google 的 Gemini。单纯用于翻译的话,注册一个账户即可使用,只要输出文本,基本是免费的(不过有使用限制,长文本输入后可能会触发限流)。
如果想使用 Gemini 的语音合成功能,则必须绑定信用卡并开通 Google 的付费账单。不同的语音合成模型收费标准不同,最基础的版本前 400 万字符免费(对个人用户来说绰绰有余),但效果一般(仍然比 Mac 自带的语音合成要好很多)。稍微高级一点的版本,前 100 万字符免费,效果则比 Mac 自带的强了一大截,非常推荐。
不过,如果你喜欢折腾,其实可以通过简单的配置,搭建一个 纯本地的 AI 翻译——即使断网也能使用,并且还能实现 AI 语音合成。
纯本地 AI 翻译方案
单纯翻译的实现非常简单,甚至不需要使用命令行即可完成。首先,可以下载一个用于运行本地大模型的 Msty,然后选择一个适合你设备配置的大模型,例如 DeepSeek 或 闻言一心。我的 MacBook 内存不多,无法运行特别大的模型,但翻译任务仍然可以顺利完成。
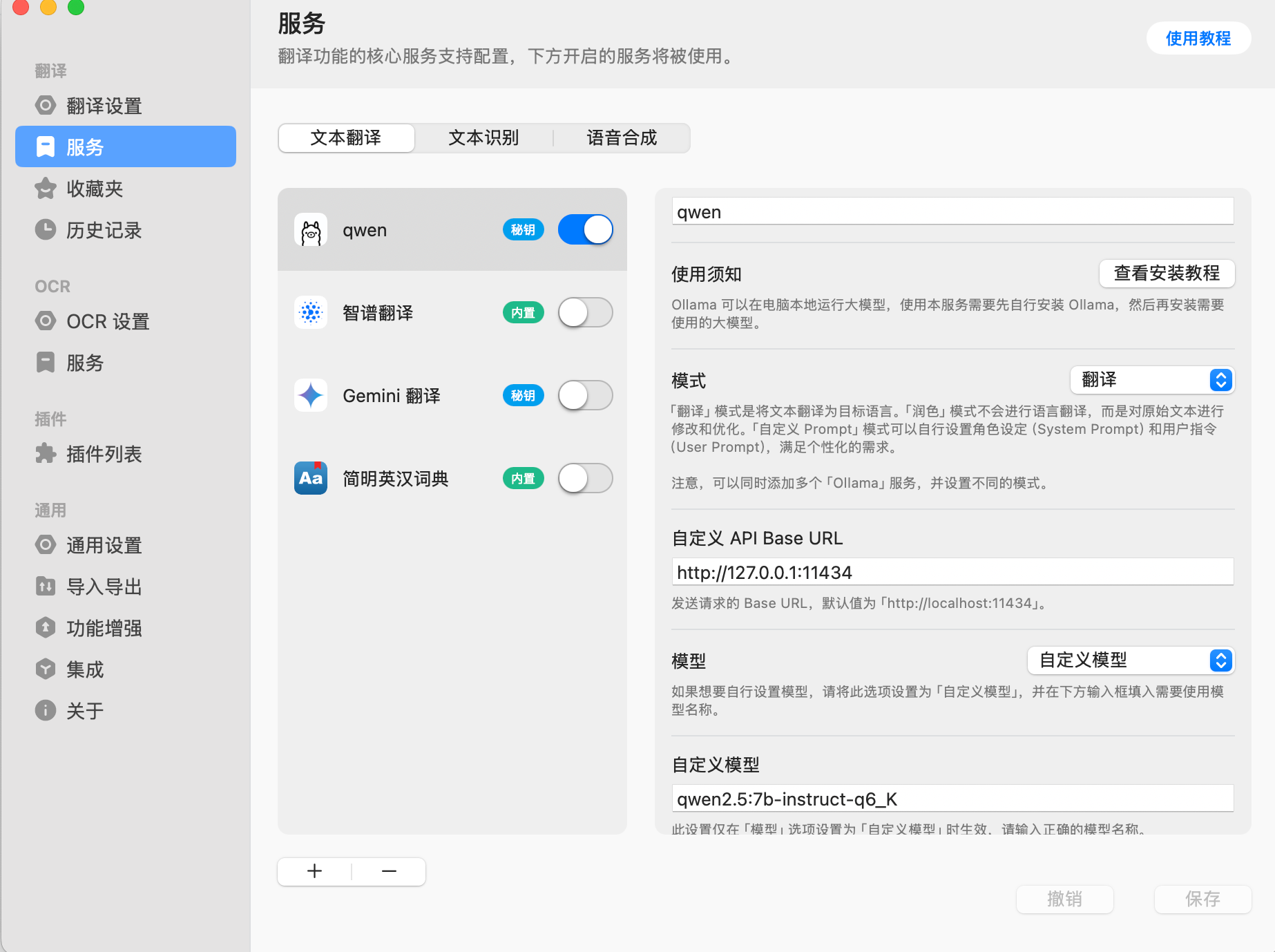
目前,我在本地运行的是 qwen2.5:7b-instruct-q6_K,测试下来是我这台 MacBook 能够流畅运行且效果最好的模型。启动成功后,只需要进行简单的配置即可。一开始,我为模型写了一个相当复杂的 Prompt,结果导致输出极慢,最终索性不写 Prompt,发现效果依然不错。
端口配置注意事项
在 Msty 里,本地大模型的接口通常是 http://localhost:10000(端口可以自行修改)。然而,Bob 里 Ollama 默认的 API 地址是 http://127.0.0.1:11434。我一开始在 Bob 里将端口地址配置为 http://127.0.0.1:10000,结果始终无法连接,最后通过本地端口转发,将 10000 端口转发到 11434,然后在 Bob 里配置 http://127.0.0.1:11434,才最终成功连接。
1 |
|
运行模型时的名称匹配
另一个需要注意的点是 大模型的名称必须严格匹配。Bob 需要精确指定运行的模型名称,例如我运行的是 qwen2.5:7b-instruct-q6_K,如果只填写 qwen2.5:7b,Bob 将无法识别。此外,我还发现,在 Bob 里设置 Prompt 对本地大模型似乎没有效果,必须在 Msty 内部修改才会生效。
配置本地语音识别
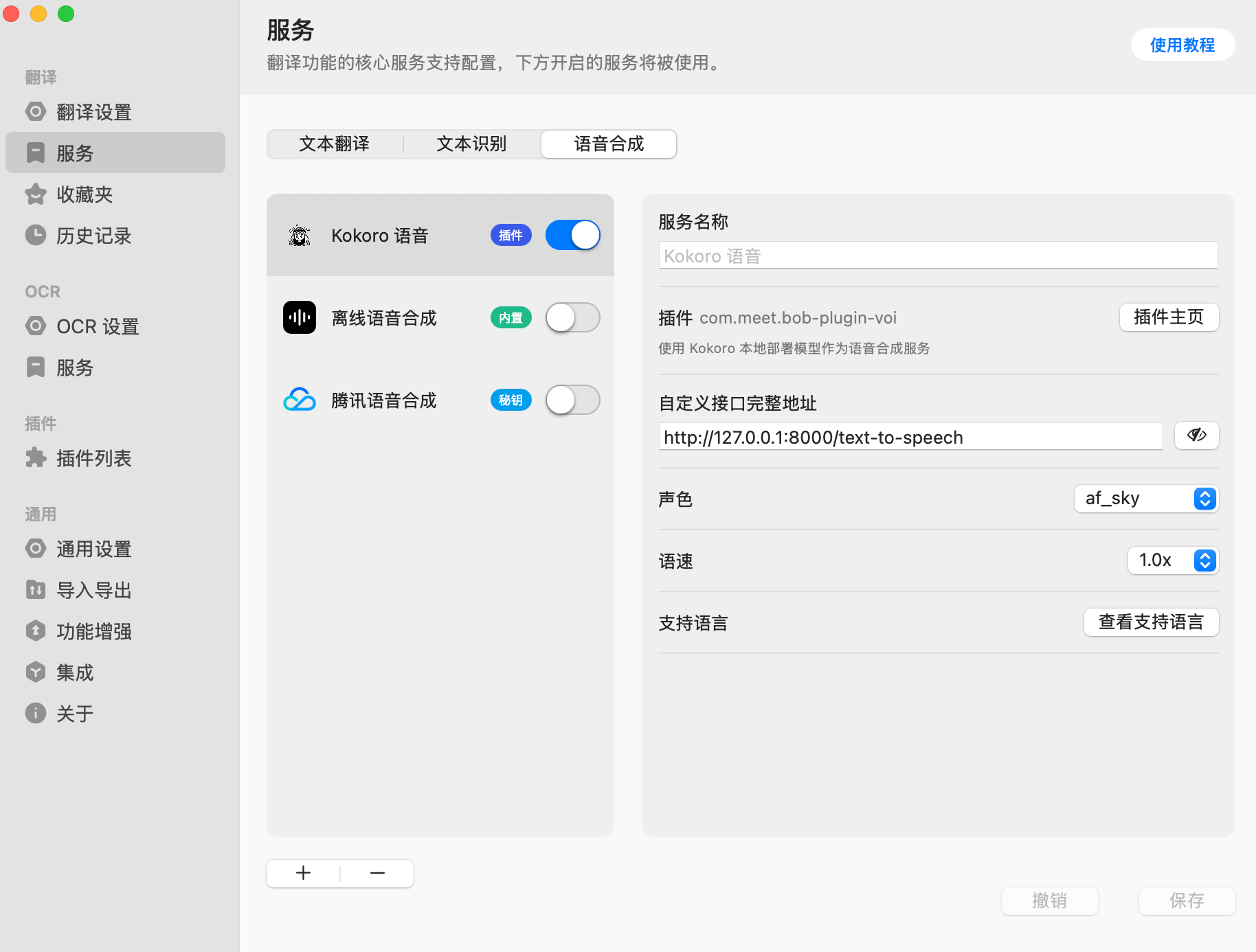
在完成纯本地翻译后,下一步是配置本地的语音识别。我使用了 Voi 这个项目:Voi GitHub。Voi 作者使用了一个目前非常热门的 TTS(文本转语音)模型 Kokoro-82M,从名字就能看出其体积非常小。实际使用后,我发现输出的音频质量相当不错,至少不输给 Google 最便宜的语音合成方案。此外,还有一个我很喜欢的项目 audiblez(audiblez GitHub),它使用的也是 Kokoro-82M,专门用于将 EPUB 转换为有声书,效果同样很出色。
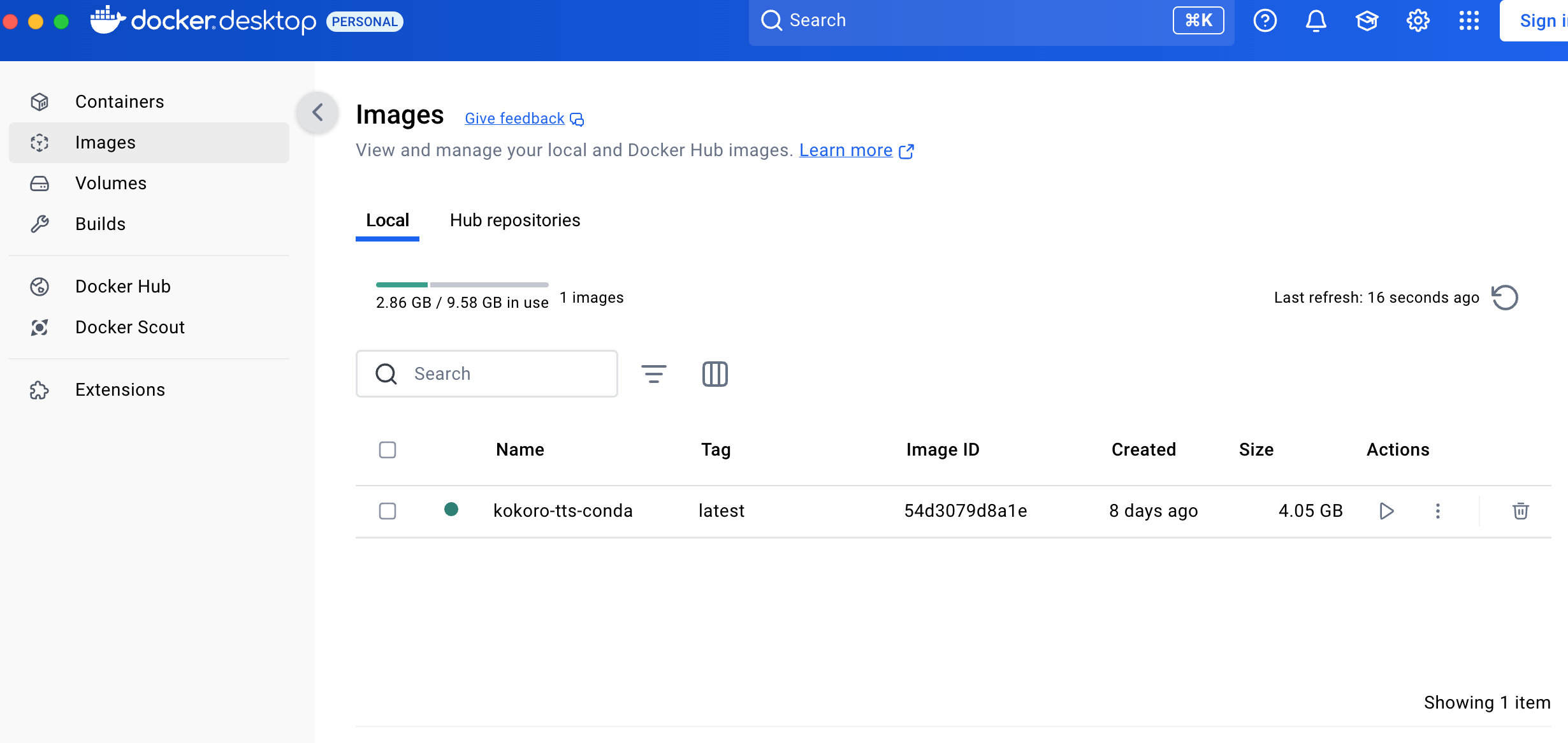
值得一提的是,Voi 的作者开发了一个专门适配 Bob 的插件(Bob官方的插件页面),因此配置过程非常简单。我直接用 Docker 拉取 Voi 到本地,并将插件上传到 Bob,随后填入默认的 API 接口:
1 |
|
这样就可以直接使用本地 TTS 了。由于我主要阅读英文材料,默认的语音听起来非常自然,十分契合我的需求。
结论
到目前为止,我的本地 AI 方案如下:
Msty 运行 qwen2.5:7b-instruct-q6_K 进行翻译。
Docker 运行 Kokoro-82M 进行文本转语音。
即便完全断网,这两个模型仍然可以正常提供翻译和语音合成服务。不过需要注意的是,由于我的设备配置一般(M1 MacBook Air),同时运行两个离线 AI 模型会占用较多内存。因此,在日常在线使用时,我仍然推荐使用 Google Gemini 或微软的 AI 服务,以获得更流畅的体验。未来,我计划进一步优化本地 AI 的运行效率,探索更适合低配设备的 AI 方案,让 AI 翻译和 TTS 能够在更多设备上稳定运行。